Consider a random variable X obtained from a random experiment E with the mean, variance  and density function
and density function  .
.
First- and Second-order approximations. The mean and variance provide a simple, partial statistical description of the random variable X that is easy to understand intuitively: the mean is the center of mass of the distribution , while the standard deviation 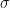 is a measure of the spread of the distribution away from the mean. The complete statistical description of X is of course provided by the density function .
is a measure of the spread of the distribution away from the mean. The complete statistical description of X is of course provided by the density function .
Specifying a distribution by its moments. An alternative statistical description of a random variable is in terms of its moments: ![\mu_n^n \doteq E \left[ X^n \right],~n=1,2, \dots \infty](https://s0.wp.com/latex.php?latex=%5Cmu_n%5En+%5Cdoteq+E+%5Cleft%5B+X%5En+%5Cright%5D%2C%7En%3D1%2C2%2C+%5Cdots+%5Cinfty&bg=ffffff&fg=111111&s=0&c=20201002) . To understand the moments of a distribution intuitively, consider the characteristic function
. To understand the moments of a distribution intuitively, consider the characteristic function ![\Phi_X(\omega) \doteq E \left[ e^{j \omega X} \right]](https://s0.wp.com/latex.php?latex=%5CPhi_X%28%5Comega%29+%5Cdoteq+E+%5Cleft%5B+e%5E%7Bj+%5Comega+X%7D+%5Cright%5D&bg=ffffff&fg=111111&s=0&c=20201002) . Mathematically, the characteristic function is the Fourier transform of the density function . For low “frequencies”
. Mathematically, the characteristic function is the Fourier transform of the density function . For low “frequencies” 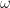 , we can approximate the characteristic function by a Taylor Series:
, we can approximate the characteristic function by a Taylor Series:  .
.
Roughly speaking, the lower-order moments provide a coarse, “low frequency” approximation to the distribution, and higher-order moments supply finer-grained “high-frequency” details.
The Law of Large Numbers. Consider N independent repetitions of the experiment E resulting in the iid sequence of random variables  . The sample mean random variable
. The sample mean random variable  has the mean
has the mean 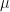 and variance
and variance  .
.
Clearly, since the variance of S vanishes as 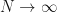 , the random variable S converges to its mean. This is also easily confirmed from
, the random variable S converges to its mean. This is also easily confirmed from  . This is one version of the famous Law of Large Numbers (LLN).
. This is one version of the famous Law of Large Numbers (LLN).
Deviations from the Mean. The LLN represents a first-order approximation to the distribution of the sample mean S. To refine this approximation and look at how S is distributed around its mean, consider the “centered random variable”  . This random variable has the characteristic function
. This random variable has the characteristic function  . This is simply the LLN all over again i.e.
. This is simply the LLN all over again i.e.  . It turns out that deviations from the mean, being second-order effects, are small and vanish asymptotically!
. It turns out that deviations from the mean, being second-order effects, are small and vanish asymptotically!
Central Limits. To prevent the deviations from the sample mean from becoming vanishingly small, we must magnify or zoom into them explicitly. Thus, we are led to define  . This random variable has zero mean and variance which is finite and its characteristic function is:
. This random variable has zero mean and variance which is finite and its characteristic function is:  .
.
This is a version of the famous Central Limit Theorem (CLT) that says that the small deviations around the sample mean of a large number of independent random variables 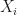 follow a Gaussian distribution regardless of the actual distribution of the ‘s!
follow a Gaussian distribution regardless of the actual distribution of the ‘s!
Random Mixing Smooths over Fine Details. In fact our simple derivation above does not require that the ‘s be identically distributed; only that they have the same mean and variance and that they are independent.
The CLT may help explain why the Bell Curve of the Gaussian distribution is so ubiquitous in nature: for complex, multi-causal natural phenomena, when we look at the aggregate of many small independent variables, the fine details of the underlying variables tend to get obscured.
There are many Internet resources that provide nice illustrations of the CLT. Here’s one from this website:

However, it is important to recognize that the CLT is an asymptotic result and usually applies in practice as an approximation. Following the logic of the derivation above, we should expect the CLT to only account for the coarse features of the distribution; in particular, the Gaussian approximation should not be relied on to predict the probability of rare “tail events”.
One place where the Gaussian approximation works really well is for the distribution of noise voltages in circuits. This is understandable when the noise is thermal in origin. Of course noise voltages are random waveforms, and their statistical description is more complex than that of a single random variable. In particular, we need to discuss the joint distribution of multiple Gaussian random variables or equivalently, Gaussian random vectors. This is a topic for Part 2.



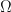 is a very small resistance – the Ohm is a poor unit for resistance!
is a very small resistance – the Ohm is a poor unit for resistance!
 and let
and let  , be the conditional probability that the process takes the value
, be the conditional probability that the process takes the value  at time
at time  given
given  .
. . This holds for all
. This holds for all  , but we will now specialize to a causal sequence of time instants
, but we will now specialize to a causal sequence of time instants  and so on. Again using The Law of Total Probability, we can write:
and so on. Again using The Law of Total Probability, we can write:  .
.  which is sometimes called the Master Equation (ME) – a rather grandiose name for a fairly humble observation.
which is sometimes called the Master Equation (ME) – a rather grandiose name for a fairly humble observation.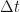 , the change
, the change  must also be infinitesimally small. Specifically, we will assume that
must also be infinitesimally small. Specifically, we will assume that  is zero for all values of
is zero for all values of  . The same is true of course of the product
. The same is true of course of the product  . A standard method in the theory of stochastic processes is represent this product by a Taylor Series to obtain the so-called Kramers-Moyal expansion to express the Master Equation in a differential form. A truncation of this Taylor Series yields the famous Fokker-Planck equation.
. A standard method in the theory of stochastic processes is represent this product by a Taylor Series to obtain the so-called Kramers-Moyal expansion to express the Master Equation in a differential form. A truncation of this Taylor Series yields the famous Fokker-Planck equation. 
 . Let
. Let  be the (random) increment in
be the (random) increment in  and write a Taylor Series for the integrand. This, however, is a road to nowhere: Taylor Series are useful over a limited range of values for
and write a Taylor Series for the integrand. This, however, is a road to nowhere: Taylor Series are useful over a limited range of values for  , but this formulation requires integrating over all
, but this formulation requires integrating over all  .
. . According to our previous smoothness assumption, the fixed distribution
. According to our previous smoothness assumption, the fixed distribution  has finite support in
has finite support in ![\epsilon \in [-\Delta x,\Delta x]](https://s0.wp.com/latex.php?latex=%5Cepsilon+%5Cin+%5B-%5CDelta+x%2C%5CDelta+x%5D&bg=ffffff&fg=111111&s=0&c=20201002) , and so we can write
, and so we can write  . Over this small and finite range, we can perform a Taylor expansion of
. Over this small and finite range, we can perform a Taylor expansion of  .
. term and only do a Taylor expansion of the other term
term and only do a Taylor expansion of the other term  . Thus, we have for the first two Taylor Series terms:
. Thus, we have for the first two Taylor Series terms:  .
. is not a distribution over the variable of integration
is not a distribution over the variable of integration  . The subscript in
. The subscript in  is to remind ourselves that it is defined for a specific value of
is to remind ourselves that it is defined for a specific value of  .
. , We have to determine if this avoids the pitfalls that we ran into in our earlier attempts. First, note that
, We have to determine if this avoids the pitfalls that we ran into in our earlier attempts. First, note that  . Define
. Define  and
and  .
. . Note that both
. Note that both  vanish as
vanish as  and the limits
and the limits  when they are non-zero have natural physical interpretations as the drift rate and diffusion rate of the process
when they are non-zero have natural physical interpretations as the drift rate and diffusion rate of the process  by keeping only the first two terms in the Taylor expansion.
by keeping only the first two terms in the Taylor expansion.
 , and the Markov chain
, and the Markov chain  of Gaussian rvs
of Gaussian rvs ![\underline{Y} = [Y_1,~Y_2,~Y_3]^T](https://s0.wp.com/latex.php?latex=%5Cunderline%7BY%7D+%3D+%5BY_1%2C%7EY_2%2C%7EY_3%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) where
where  .
. has zero mean and the covariance:
has zero mean and the covariance:  . The lengths of the three vectors are
. The lengths of the three vectors are  . The correlation coefficient between
. The correlation coefficient between  is
is  and the angle between them is
and the angle between them is  . Likewise for
. Likewise for  we have
we have  and the angle between them is
and the angle between them is  and so on.
and so on. . This is straightforward because knowing
. This is straightforward because knowing  , but since
, but since  are independent of
are independent of  , their distributions do not change. Thus we have
, their distributions do not change. Thus we have  . The conditional means of
. The conditional means of ![[Y_2,~Y_3]^T](https://s0.wp.com/latex.php?latex=%5BY_2%2C%7EY_3%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) is
is ![[a,~a]^T](https://s0.wp.com/latex.php?latex=%5Ba%2C%7Ea%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) and their conditional covariance is
and their conditional covariance is  .
. . This is not as straightforward as the previous case because
. This is not as straightforward as the previous case because  is correlated with all three of
is correlated with all three of  and all of their distributions will change when we condition on
and all of their distributions will change when we condition on  . But we want to avoid this brute-force approach and would like to find a more elegant, intuitive method. We now show how to do this using geometric manipulations with vectors.
. But we want to avoid this brute-force approach and would like to find a more elegant, intuitive method. We now show how to do this using geometric manipulations with vectors. and
and  . (Note that we cannot show all three vectors representing
. (Note that we cannot show all three vectors representing  on the same planar vector diagram and preserve geometric relationships such as angles; this is because the three rvs are linearly independent which means the corresponding vectors are not coplanar.)
on the same planar vector diagram and preserve geometric relationships such as angles; this is because the three rvs are linearly independent which means the corresponding vectors are not coplanar.)
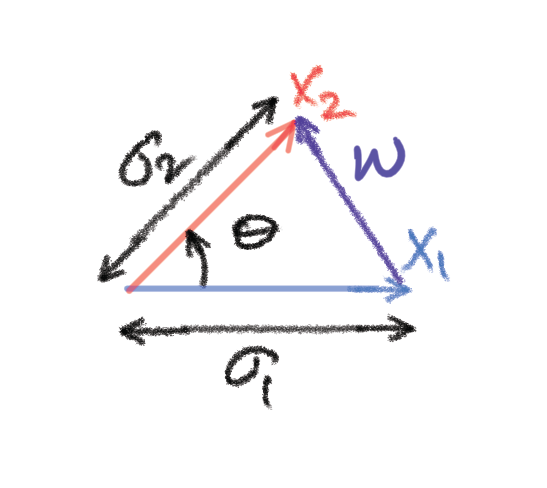
 in the direction of
in the direction of  as the sum of two component vectors, one
as the sum of two component vectors, one  that is perfectly aligned with
that is perfectly aligned with  for some constant
for some constant 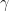 . We need to find this constant in terms of the statistics of
. We need to find this constant in terms of the statistics of  .
. denote the unit vector in the direction of
denote the unit vector in the direction of  . From the trigonometry of the right-angled triangle formed by the vectors
. From the trigonometry of the right-angled triangle formed by the vectors  , we have
, we have  and
and  which gives
which gives  and
and  .
. , where
, where  is independent of
is independent of  . Similarly, we can show that
. Similarly, we can show that  .
. . Note that since both
. Note that since both  are independent of
are independent of  .
.
![\underline{X} \doteq [X_1,~X_2,~\dots, X_N]^T](https://s0.wp.com/latex.php?latex=%5Cunderline%7BX%7D+%5Cdoteq+%5BX_1%2C%7EX_2%2C%7E%5Cdots%2C+X_N%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) as a column vector with joint Gaussian rvs
as a column vector with joint Gaussian rvs  . We may use the distribution
. We may use the distribution  as a short-hand for the joint distribution of the
as a short-hand for the joint distribution of the 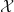 of random variables. Of course, being random variables, each of the
of random variables. Of course, being random variables, each of the  are jointly Gaussian rvs represented by vectors of lengths
are jointly Gaussian rvs represented by vectors of lengths  respectively. The angle between them is related to the correlation coefficient as
respectively. The angle between them is related to the correlation coefficient as  .
.
 . Its variance can be calculated algebraically as
. Its variance can be calculated algebraically as  . It is easily checked that this matches exactly the well-known elementary geometric relationship between the sides of a triangle:
. It is easily checked that this matches exactly the well-known elementary geometric relationship between the sides of a triangle:  .
.![\underline{Z} \doteq [Z_1, Z_2 \dots Z_M]^T](https://s0.wp.com/latex.php?latex=%5Cunderline%7BZ%7D+%5Cdoteq+%5BZ_1%2C+Z_2+%5Cdots+Z_M%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) , and a sequence of derived random variables
, and a sequence of derived random variables  , where A is a
, where A is a  matrix. Thus
matrix. Thus ![\underline{X} \doteq [X_1, X_2 \dots X_N]^T](https://s0.wp.com/latex.php?latex=%5Cunderline%7BX%7D+%5Cdoteq+%5BX_1%2C+X_2+%5Cdots+X_N%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002) is a sequence of random variables that are linear combinations of the
is a sequence of random variables that are linear combinations of the  ‘s.
‘s. and create nice, little baby Gaussians like e.g.
and create nice, little baby Gaussians like e.g.  . These are the nice, natural kind of Gaussians we discussed above.
. These are the nice, natural kind of Gaussians we discussed above.
 where
where  is equal to
is equal to  depending on the sign of
depending on the sign of  . Randomly flipping the sign of a zero mean Gaussian still yields a Gaussian rv because of the even symmetry of the Gaussian density function. The new rv
. Randomly flipping the sign of a zero mean Gaussian still yields a Gaussian rv because of the even symmetry of the Gaussian density function. The new rv  , but certainly not independent of it. The mixture
, but certainly not independent of it. The mixture  is very far from a Gaussian: it is zero with 50% probability!
is very far from a Gaussian: it is zero with 50% probability!